隨著企業數據規模的爆炸式增長和業務對實時性、敏捷性要求的不斷提升,傳統的Hadoop架構因其緊耦合的存算一體模式,在資源彈性、運維成本和技術演進上面臨著顯著挑戰。在此背景下,以Hadoop存算分離為基礎,構建云原生數據存儲管理與數據處理服務,已成為大數據平臺現代化演進的核心路徑。本文將深入解析這一架構的核心理念、關鍵技術與實現方案。
一、 從存算一體到存算分離:架構演進的內在邏輯
傳統Hadoop(以HDFS + YARN + MapReduce/Spark為代表)將存儲(HDFS)與計算(計算框架)深度綁定在同一批物理節點上。這種設計在早期帶來了數據本地性優勢,減少了網絡傳輸開銷。但隨著云計算的普及和業務需求的變化,其弊端日益凸顯:
- 資源利用不均:存儲和計算資源無法獨立擴展,容易造成一方資源閑置而另一方資源緊張。
- 彈性能力不足:擴容或縮容需同時調整存儲和計算節點,流程復雜,無法快速響應業務波動。
- 成本高昂:為滿足峰值計算需求,往往需要過度配置存儲資源,導致總體擁有成本(TCO)上升。
- 技術棧鎖死:計算引擎與HDFS強綁定,難以靈活引入新的數據處理框架或對象存儲等新型存儲。
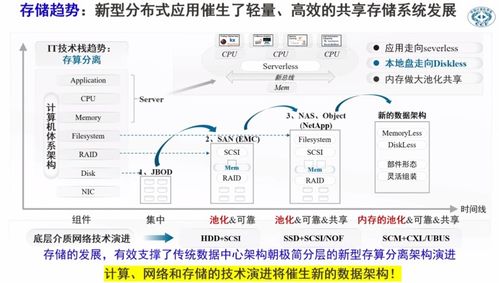
存算分離的核心思想正是解耦存儲與計算。存儲層采用獨立、可擴展的分布式存儲服務(如對象存儲、云原生分布式文件系統),計算層則變為無狀態的、可按需彈性伸縮的容器化集群。兩者通過高速網絡連接,計算層按需訪問遠端統一的數據湖存儲。
二、 Hadoop存算分離的云原生實現路徑
實現Hadoop生態的存算分離,并非簡單替換HDFS,而是一個系統性工程,主要涉及以下層面:
1. 存儲層云原生化:構建統一數據湖存儲
- 存儲選型:采用與云環境深度集成的對象存儲服務(如AWS S3、Azure Blob Storage、阿里云OSS、華為云OBS)或兼容S3協議的分布式文件系統(如Ceph、MinIO)。這些服務提供近乎無限的擴展能力、高耐久性和按使用量付費的模式。
- 數據組織與元數據管理:雖然原始數據存儲在對象存儲中,但目錄結構、文件權限、事務支持等“類文件系統”的元數據管理仍需解決。常用方案包括:
- 使用HDFS Namenode的優化版本:如騰訊云COSN、阿里云JindoFS、華為云OBS-FS,它們通過實現HDFS文件系統接口,將元數據與數據分離,元數據由獨立服務管理,數據則落地對象存儲。
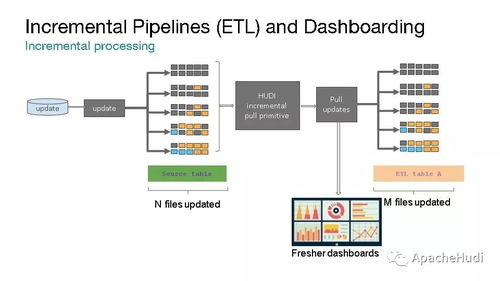
- 采用Lakehouse架構的元數據層:如Apache Hudi、Delta Lake、Apache Iceberg。它們在對象存儲之上構建了具有ACID事務、版本管理、高效Upsert/Delete能力的表格式層,成為連接計算引擎與底層存儲的“智能中間層”,是實現存算分離和高級數據管理的關鍵。
2. 計算層容器化與彈性化
- 計算框架適配:主流計算引擎(如Spark、Flink、Presto/Trino、Hive)均已支持直接讀寫對象存儲(通過
S3A、OSS等連接器)或上述表格式。任務運行時從對象存儲拉取數據。
- 資源管理與調度云原生化:放棄YARN,轉而使用Kubernetes作為統一的容器編排與資源調度平臺。計算任務(Spark Job、Flink Session等)被封裝為Kubernetes Pod,由K8s負責其生命周期管理、資源調度、彈性伸縮(HPA/VPA)和高可用保障。這實現了極致的計算資源彈性和運維自動化。
3. 數據訪問與緩存加速
網絡延遲是存算分離的主要顧慮。為保障性能,需構建多層次緩存體系:
- 計算側本地緩存:Spark/Flink等任務在計算節點本地SSD或內存中緩存熱數據塊。
- 分布式緩存層:部署獨立的分布式緩存集群(如Alluxio、JindoFS緩存模式),作為計算集群與對象存儲之間的透明加速層。它能聚合計算節點的內存和SSD,提供POSIX或HDFS接口,對熱數據進行集中緩存和智能預取,顯著降低訪問延遲和對象存儲的出口帶寬成本。
三、 實現云原生數據存儲管理與數據處理服務
基于上述架構,可以構建一個完整的云原生數據平臺服務:
- 統一的數據湖存儲服務:對象存儲作為企業數據的單一可信來源,承載原始數據、清洗后數據、模型數據等。結合Delta Lake/Iceberg等表格式,提供數據版本、模式演進、時間旅行、增量更新等企業級數據管理能力。
- 彈性的數據處理服務:
- 按需啟停的計算集群:數據處理任務(ETL、流處理、即席查詢)以容器化方式運行在K8s上,任務完成后資源立即釋放,實現“零閑置成本”。
- Serverless交互式查詢:利用Presto/Trino on K8s,配合資源自動伸縮,為用戶提供秒級啟動、按查詢付費的交互式分析服務。
- 統一的工作流編排:使用Airflow、Kubeflow Pipelines等云原生友好的工具進行任務編排和MLOps管理,所有任務均調度到K8s集群執行。
- 智能的數據治理與安全:在云原生環境下,可集成統一的權限管理(如Ranger、AWS IAM)、數據血緣、質量監控和成本分析工具,實現跨存儲和計算資源的精細化管控。
四、 優勢與挑戰
優勢:
- 極致彈性與敏捷性:存儲與計算獨立無限擴展,計算資源秒級伸縮,快速響應業務。
- 顯著降低成本:存儲采用低成本高耐久的對象存儲,計算按實際使用量付費,資源利用率大幅提升。
- 技術開放與創新:計算引擎與底層存儲解耦,便于引入新技術棧,避免供應商鎖定。
- 運維簡化:依托云平臺和K8s的自動化運維能力,降低了集群管理的復雜性。
挑戰與考量:
- 網絡性能與成本:需優化網絡架構(如使用VPC內網、高速通道)并合理設計緩存策略,以平衡延遲與成本。
- 數據一致性語義:對象存儲的“最終一致性”模型與HDFS的“強一致性”存在差異,需通過表格式層或客戶端適配來滿足業務要求。
- 生態工具適配:部分傳統Hadoop生態工具(如某些舊版本的Sqoop、特定依賴HDFS API的應用)需要改造或替換。
###
Hadoop存算分離并邁向云原生,是大數據平臺應對云時代挑戰的必然選擇。它并非顛覆Hadoop生態,而是對其核心價值的繼承與升華——將Hadoop豐富的計算生態與云原生的彈性、敏捷和成本優勢相結合。通過采用對象存儲、容器化計算、智能數據湖格式及緩存加速等技術,企業能夠構建一個存儲無限擴展、計算瞬時可得、管理智能統一的現代化數據平臺,從而更好地賦能數據驅動業務創新。