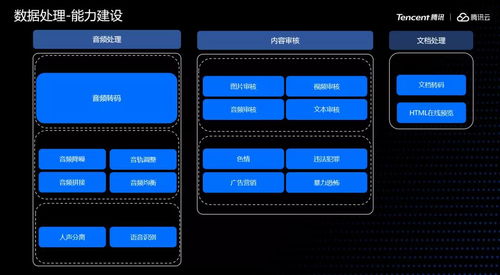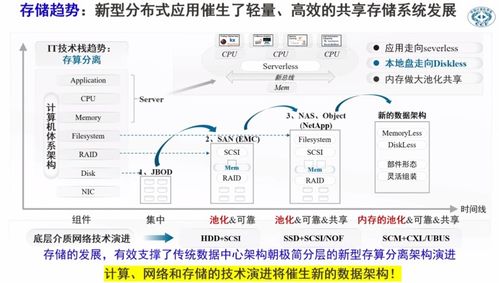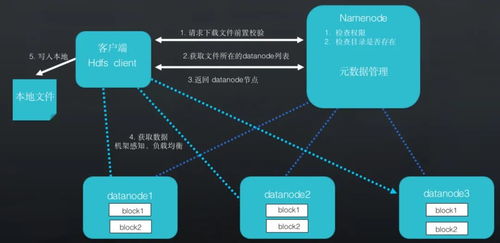
一、概述
數(shù)據(jù)處理與存儲(chǔ)服務(wù)是HCIP存儲(chǔ)服務(wù)規(guī)劃中的核心模塊,它聚焦于數(shù)據(jù)從產(chǎn)生、處理到最終存儲(chǔ)的全生命周期管理。在現(xiàn)代數(shù)據(jù)中心和云環(huán)境中,數(shù)據(jù)不僅是靜態(tài)的存儲(chǔ)對(duì)象,更是需要被實(shí)時(shí)或近實(shí)時(shí)處理、分析并轉(zhuǎn)化為業(yè)務(wù)價(jià)值的動(dòng)態(tài)資產(chǎn)。本模塊旨在規(guī)劃如何將數(shù)據(jù)處理能力與存儲(chǔ)基礎(chǔ)設(shè)施無(wú)縫集成,構(gòu)建高效、智能的數(shù)據(jù)管道。
二、數(shù)據(jù)處理服務(wù)規(guī)劃
數(shù)據(jù)處理服務(wù)負(fù)責(zé)對(duì)原始數(shù)據(jù)進(jìn)行清洗、轉(zhuǎn)換、分析和價(jià)值提取。規(guī)劃時(shí)需考慮以下關(guān)鍵方面:
- 處理范式與框架選擇:
- 批處理:適用于對(duì)海量歷史數(shù)據(jù)進(jìn)行離線分析,如使用Hadoop MapReduce、Spark等框架。規(guī)劃需考慮計(jì)算集群與存儲(chǔ)(如HDFS、對(duì)象存儲(chǔ))的部署模式(分離或超融合)、數(shù)據(jù)本地性優(yōu)化以及作業(yè)調(diào)度策略。
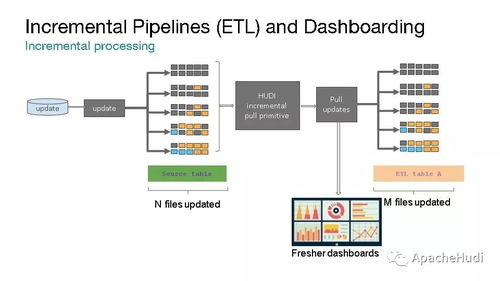
- 流處理:適用于對(duì)實(shí)時(shí)產(chǎn)生的事件流(如日志、IoT傳感器數(shù)據(jù))進(jìn)行即時(shí)處理,如使用Flink、Spark Streaming、Kafka Streams。規(guī)劃重點(diǎn)在于消息隊(duì)列(如Kafka)的容量與性能、流處理引擎的容錯(cuò)性與狀態(tài)管理,以及與下游存儲(chǔ)系統(tǒng)的低延遲寫(xiě)入集成。
- 交互式查詢:適用于即席分析與數(shù)據(jù)探索,如使用Presto、Impala、ClickHouse。規(guī)劃需關(guān)注計(jì)算資源彈性、元數(shù)據(jù)管理以及與底層存儲(chǔ)格式(如Parquet、ORC)的適配優(yōu)化。
2. 計(jì)算與存儲(chǔ)分離架構(gòu):
現(xiàn)代趨勢(shì)是將無(wú)狀態(tài)的計(jì)算層與持久化的存儲(chǔ)層解耦。此架構(gòu)的優(yōu)勢(shì)在于計(jì)算與存儲(chǔ)可獨(dú)立擴(kuò)展,資源利用率高,成本更優(yōu)。規(guī)劃時(shí)需確保網(wǎng)絡(luò)帶寬和延遲能滿足數(shù)據(jù)在計(jì)算節(jié)點(diǎn)與存儲(chǔ)服務(wù)(如對(duì)象存儲(chǔ)S3、OBS)間高效傳輸?shù)囊螅⑦x擇支持該架構(gòu)的數(shù)據(jù)處理引擎(如云原生Spark、Flink)。
3. 數(shù)據(jù)處理流水線(Data Pipeline)編排:
使用工作流編排工具(如Apache Airflow、Kubeflow Pipelines)來(lái)定義、調(diào)度和監(jiān)控復(fù)雜的數(shù)據(jù)處理任務(wù)依賴關(guān)系。規(guī)劃需設(shè)計(jì)清晰的任務(wù)DAG(有向無(wú)環(huán)圖),設(shè)置合理的重試、告警機(jī)制,并確保流水線各環(huán)節(jié)與存儲(chǔ)服務(wù)的認(rèn)證、授權(quán)集成。
三、存儲(chǔ)服務(wù)規(guī)劃
存儲(chǔ)服務(wù)是數(shù)據(jù)持久化的基石,需要根據(jù)數(shù)據(jù)處理的需求和數(shù)據(jù)的特性來(lái)選擇合適的存儲(chǔ)類型與策略。
- 分級(jí)存儲(chǔ)與生命周期管理:
- 熱數(shù)據(jù)層:存放需要被頻繁、快速訪問(wèn)的數(shù)據(jù),如數(shù)據(jù)庫(kù)、實(shí)時(shí)分析表。通常采用高性能的塊存儲(chǔ)(如SSD云硬盤)或低延遲的對(duì)象存儲(chǔ)。
- 溫?cái)?shù)據(jù)層:存放訪問(wèn)頻率適中的數(shù)據(jù),如每周或每月的分析報(bào)表。可采用性能與成本均衡的存儲(chǔ)類型。
- 冷/歸檔數(shù)據(jù)層:存放極少訪問(wèn)但需長(zhǎng)期保留的數(shù)據(jù),如合規(guī)性備份、歷史日志。采用高密度、低成本的存儲(chǔ)(如磁帶、歸檔級(jí)對(duì)象存儲(chǔ))。
- 規(guī)劃要點(diǎn):制定自動(dòng)化的數(shù)據(jù)生命周期策略,根據(jù)時(shí)間、訪問(wèn)模式等屬性,在存儲(chǔ)層間自動(dòng)遷移數(shù)據(jù),實(shí)現(xiàn)成本優(yōu)化。
- 數(shù)據(jù)格式與存儲(chǔ)優(yōu)化:
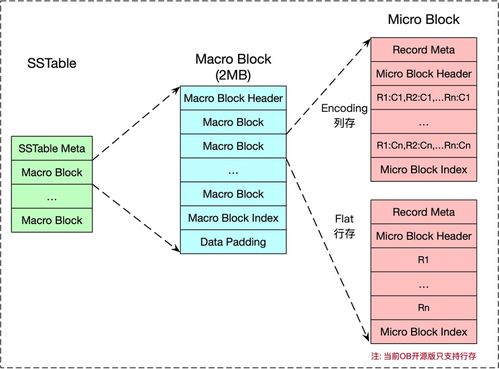
- 列式存儲(chǔ)(如Parquet, ORC):對(duì)于分析型負(fù)載,能極大減少I/O,提升查詢性能。規(guī)劃時(shí)需根據(jù)查詢模式選擇合適的分區(qū)鍵、排序鍵和壓縮算法。
- 索引與緩存:為關(guān)鍵數(shù)據(jù)路徑(如數(shù)據(jù)庫(kù)、熱點(diǎn)文件)規(guī)劃索引策略(如Bloom Filter)和多級(jí)緩存(如計(jì)算側(cè)緩存、存儲(chǔ)側(cè)緩存),以加速數(shù)據(jù)定位與讀取。
- 存儲(chǔ)服務(wù)與數(shù)據(jù)處理集成:
- 統(tǒng)一元數(shù)據(jù)目錄:規(guī)劃一個(gè)中心化的元數(shù)據(jù)服務(wù)(如Hive Metastore, AWS Glue Data Catalog),使不同的數(shù)據(jù)處理引擎能夠以一致的視角發(fā)現(xiàn)和訪問(wèn)存儲(chǔ)在異構(gòu)系統(tǒng)(HDFS, 對(duì)象存儲(chǔ),數(shù)據(jù)庫(kù))中的數(shù)據(jù)。
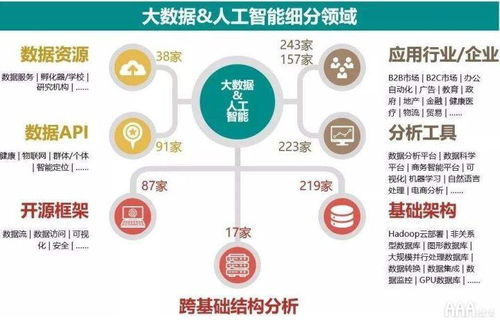
- 數(shù)據(jù)湖/湖倉(cāng)一體架構(gòu):規(guī)劃以對(duì)象存儲(chǔ)為中心的數(shù)據(jù)湖作為原始數(shù)據(jù)的統(tǒng)一存儲(chǔ)池,其上通過(guò)元數(shù)據(jù)層、數(shù)據(jù)處理引擎和可能的專用數(shù)倉(cāng)層(湖倉(cāng)一體),支撐從原始數(shù)據(jù)處理到高性能分析的全場(chǎng)景。重點(diǎn)規(guī)劃數(shù)據(jù)入湖的格式標(biāo)準(zhǔn)化、元數(shù)據(jù)管理和數(shù)據(jù)治理流程。
四、核心考量與最佳實(shí)踐
- 性能與成本平衡:始終在存儲(chǔ)性能、數(shù)據(jù)可靠性、訪問(wèn)延遲和總體擁有成本(TCO)之間尋求最佳平衡點(diǎn)。利用分級(jí)存儲(chǔ)和彈性伸縮來(lái)動(dòng)態(tài)調(diào)整。
- 數(shù)據(jù)一致性與可靠性:根據(jù)業(yè)務(wù)需求,為不同數(shù)據(jù)定義明確的一致性模型(強(qiáng)一致、最終一致)和持久性要求(副本數(shù)、糾刪碼策略、跨區(qū)域復(fù)制)。
- 安全與合規(guī):規(guī)劃貫穿數(shù)據(jù)處理與存儲(chǔ)全鏈路的加密(傳輸中/靜態(tài))、細(xì)粒度訪問(wèn)控制(IAM策略、桶策略、文件ACL)、審計(jì)日志以及數(shù)據(jù)脫敏機(jī)制。
- 可觀測(cè)性與運(yùn)維:建立完善的監(jiān)控體系,覆蓋存儲(chǔ)服務(wù)的容量、性能(IOPS、吞吐、延遲)、可用性,以及數(shù)據(jù)處理作業(yè)的運(yùn)行狀態(tài)、資源消耗和SLA達(dá)成情況。實(shí)現(xiàn)自動(dòng)化告警與故障自愈。
五、
數(shù)據(jù)處理與存儲(chǔ)服務(wù)的規(guī)劃是一個(gè)系統(tǒng)性工程,需要從業(yè)務(wù)目標(biāo)、數(shù)據(jù)特征和技術(shù)趨勢(shì)出發(fā)進(jìn)行通盤設(shè)計(jì)。成功的規(guī)劃應(yīng)能構(gòu)建一個(gè)彈性、高效、智能且成本可控的數(shù)據(jù)基礎(chǔ)設(shè)施,使得數(shù)據(jù)能夠順暢流動(dòng),并高效地轉(zhuǎn)化為洞察與決策,從而賦能業(yè)務(wù)創(chuàng)新與發(fā)展。在HCIP認(rèn)證的語(yǔ)境下,深入理解并能夠設(shè)計(jì)此類方案,是具備企業(yè)級(jí)存儲(chǔ)解決方案規(guī)劃能力的重要體現(xiàn)。