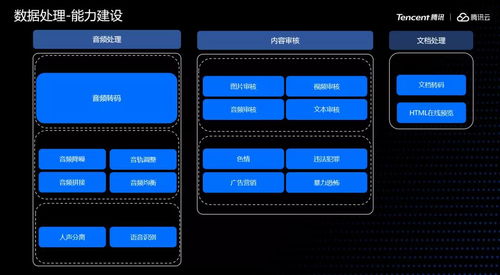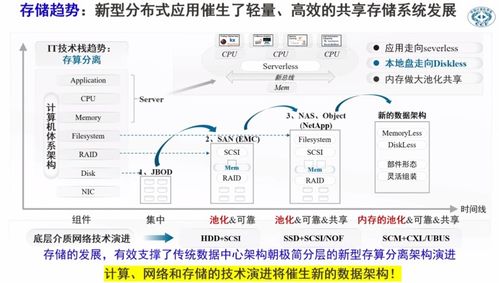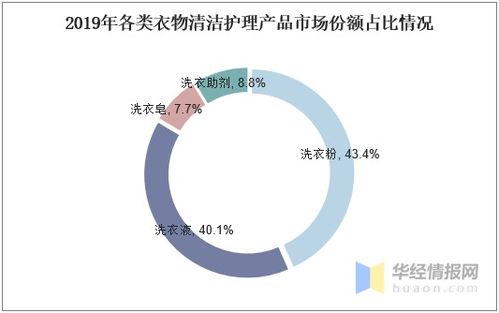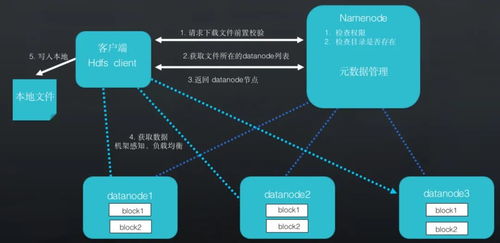
在當今數據驅動的時代,企業面臨著對海量數據進行高效批處理和近實時分析的巨大挑戰。傳統的數據架構往往將批處理與流處理割裂,導致數據孤島、處理延遲和運維復雜。Apache Hudi(Hadoop Upserts Deletes and Incrementals)應運而生,它作為一個開源的數據湖框架,旨在通過統一的數據存儲與服務層,彌合批處理與流處理之間的鴻溝,提供增量數據處理、高效的更新刪除以及近實時的數據可見性。
一、Hudi 的核心設計理念:統一存儲與服務
Hudi 的核心價值在于其“統一”的特性。它并非取代現有的批處理(如 Apache Spark)或流處理(如 Apache Flink)計算引擎,而是作為其下的一個存儲與服務層,為上層應用提供一致、高效的數據管理能力。其設計目標包括:
- 增量處理:支持對數據湖進行記錄級的插入、更新和刪除,避免傳統批處理中全量覆蓋的低效操作。
- 近實時攝取:允許數據以分鐘甚至秒級的延遲被寫入并立即對查詢可見。
- 統一視圖:為批處理作業和交互式查詢提供同一份數據的統一視圖,確保數據一致性。
- 事務保障:提供了寫入和快照隔離級別的讀取,確保并發操作下的數據準確性。
二、關鍵技術特性:實現批流一體的基石
Hudi 通過一系列創新特性,實現了對批處理和近實時分析場景的統一支持:
- 表類型與查詢類型:
- Copy-on-Write (CoW) 表:在寫入時直接合并新數據到列存文件(如 Parquet),適合讀多寫少、追求最佳查詢性能的場景。批處理和快照查詢直接讀取最新的數據文件。
- Merge-on-Read (MoR) 表:寫入時將更新數據存入行存日志文件(如 Avro),后臺異步或按需合并到列存文件。這極大地優化了寫入延遲,特別適合寫多讀少或需要極低延遲數據可見性的近實時場景。查詢時,實時讀取會合并列存文件和日志文件以提供最新快照。
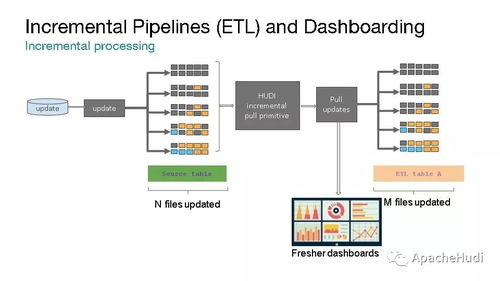
- 增量查詢:這是 Hudi 的殺手锏功能。它允許用戶從某個時間點或提交點開始,僅查詢新寫入或更改的數據,而非全表掃描。這對于構建增量 ETL 管道、同步數據到外部系統或進行近實時監控至關重要。
- 自動文件管理:Hudi 自動管理文件大小、執行壓縮(Compaction,將 MoR 表的日志文件合并到列存文件)和清理(Cleanup,刪除舊版本文件),優化存儲布局和查詢性能。
- 索引機制:Hudi 內置了多種索引(如布隆過濾器索引、HBase索引),用于在 Upsert/Delete 操作時快速定位目標數據所在文件,避免全表掃描,提升寫入效率。
三、數據處理與存儲服務:Hudi 的實際應用
在數據處理與存儲服務層面,Hudi 扮演著核心樞紐的角色:
- 數據攝取服務:
- 批量數據入湖:傳統的 T+1 批量數據可以通過 Spark 作業高效地以 Upsert 方式寫入 Hudi,避免重復和覆蓋問題。
- 近實時流式攝取:來自 Kafka 等消息隊列的流數據,可以通過 Spark Structured Streaming、Flink 等引擎持續寫入 MoR 表,實現分鐘級甚至秒級延遲的數據入湖,并立即可查。
- 數據存儲與管理服務:
- 高效的更新與刪除:滿足 GDPR “被遺忘權”等合規要求,或處理業務數據變更,Hudi 支持對海量數據湖進行記錄級更新和刪除。
- 時間旅行與版本回溯:Hudi 保留了數據的歷史版本,用戶可以查詢任意時間點的數據快照,便于審計、調試和恢復。
- 存儲優化:通過自動的壓縮和聚類(Clustering)服務,優化文件大小和數據布局,提升查詢性能。
- 數據服務與消費:
- 統一查詢服務:無論是 Presto、Trino、Spark SQL 進行的交互式分析,還是 Hive 進行的批處理報表,都可以基于同一張 Hudi 表進行,獲取一致的最新數據視圖。增量查詢功能則專門服務于下游的增量同步和近實時分析應用。
- 近實時分析:數據工程師和分析師可以基于 MoR 表的實時視圖,對剛剛入湖的數據進行即時查詢和分析,快速響應業務變化。
四、架構優勢與未來展望
采用 Apache Hudi 構建數據湖存儲層,為企業帶來了顯著優勢:簡化了數據架構,降低了批流融合的復雜性;提升了數據新鮮度和處理效率;同時保證了數據的完整性和一致性。
隨著云原生和湖倉一體(Lakehouse)架構的興起,Hudi 正持續演進,更好地與云存儲(如 AWS S3)、計算引擎以及數據治理工具集成。它正成為構建現代化、高性能、可擴展的數據平臺的關鍵組件,助力企業在統一的存儲與服務基礎上,實現從傳統批處理到智能實時分析的平滑演進。
總而言之,Apache Hudi 不僅僅是一個存儲格式,更是一個功能強大的數據湖存儲與服務引擎。它通過統一批處理和近實時分析的數據存儲層,為高效、可靠、敏捷的數據處理流水線奠定了堅實的基礎。