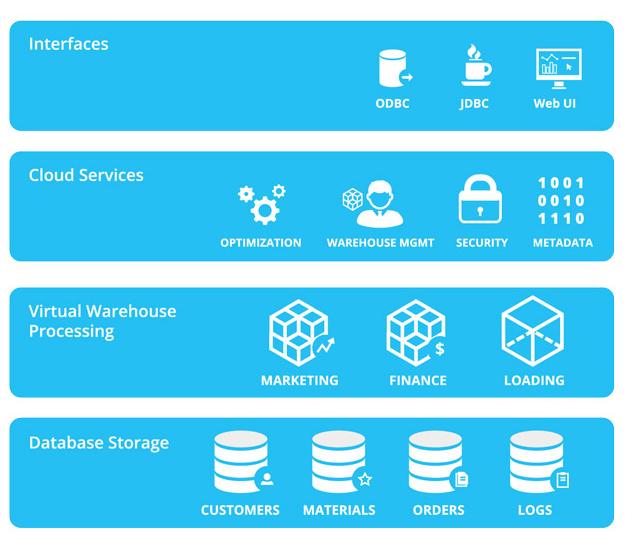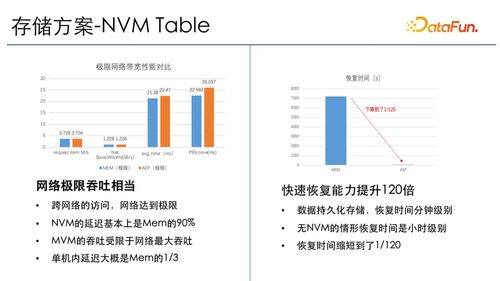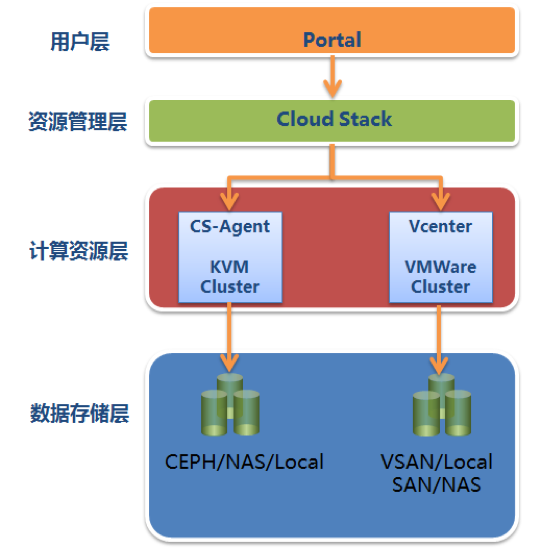
在大數據時代,Hadoop以其強大的分布式計算和存儲能力,成為處理海量數據的核心框架。僅僅擁有處理能力還不足夠,如何將處理后的數據以直觀、可理解的方式呈現出來,即大數據可視化,同樣至關重要。以國內知名技術社區CSDN為例,其數據處理與存儲服務的實踐,為Hadoop生態系統下的數據可視化應用提供了寶貴的參考。
一、Hadoop數據處理與存儲服務的核心構成
Hadoop生態系統為大數據處理與存儲提供了堅實基礎。其核心包括:
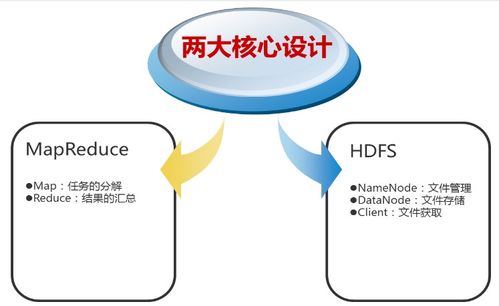
- 分布式文件系統HDFS:作為數據存儲的基石,HDFS能夠可靠地存儲PB級別的數據,并通過數據塊復制機制保證高容錯性。它為后續的數據處理提供了統一、高吞吐量的數據訪問接口。
- 分布式計算框架MapReduce/YARN:MapReduce編程模型允許開發者編寫并行處理海量數據的程序。而YARN作為資源調度器,管理著集群的計算資源,使得Spark、Flink等多種計算框架可以高效運行其上,完成復雜的數據轉換、清洗和聚合任務。
- 數據倉庫工具Hive:Hive提供了類SQL的查詢語言(HQL),將結構化數據文件映射為數據庫表,大大降低了大數據查詢和分析的門檻,是生成可視化所需匯總數據的關鍵工具。
這些組件共同構成了一個從原始數據存儲到初步處理的數據管道,為可視化準備了“原材料”。
二、大數據可視化:從數據到洞察的關鍵橋梁
數據處理之后,可視化是將數據價值傳遞給最終用戶的關鍵一步。在Hadoop生態中,可視化通常不是由Hadoop核心組件直接完成,而是通過以下方式實現:
- 數據提取與聚合:利用Hive、Spark SQL或Impala等工具,從HDFS或HBase中查詢和聚合出可視化所需的維度、指標數據。這些數據通常被匯總為結構清晰的中間結果。
- 數據導出與對接:將聚合后的結果數據導出到關系型數據庫(如MySQL)、分析型數據庫或直接通過API接口,供前端可視化工具調用。
- 可視化工具應用:前端使用專業的可視化庫(如ECharts、D3.js)或商業智能(BI)工具(如Superset、Tableau,這些工具也支持直接連接Hive等數據源),將數據轉化為圖表、儀表盤、地圖等直觀形式。
三、CSDN場景下的實踐啟示
以技術社區CSDN為例,其平臺產生了海量的用戶行為數據、文章數據、交互數據等。其數據處理與可視化流程可能涉及:
- 數據存儲:用戶日志、文章內容、評論點贊等原始數據存入HDFS,構成數據湖。
- 數據處理:通過MapReduce或Spark作業進行數據清洗(如去噪、歸一化)、關鍵指標計算(如每日活躍用戶數、熱門文章排行、技術趨勢分析)。處理后的結構化數據可存入Hive表或HBase。
- 服務與可視化:
- 對內運營:數據分析團隊使用BI工具連接Hive,制作儀表盤,實時監控社區流量、內容產出、用戶增長等核心運營指標,驅動決策。
- 對外產品:在CSDN博客、排行榜等產品頁面,后端服務從處理后的數據存儲中查詢數據,前端通過可視化圖表展示“熱門技術標簽”、“博主影響力指數”、“學習路徑推薦”等,增強用戶體驗和社區互動。
- 架構整合:CSDN的實踐很可能采用了分層架構,從原始數據層、數據倉庫層到應用數據層,Hadoop服務于底層海量數據的批處理與存儲,而上層應用和可視化則依賴于更實時、接口友好的數據服務。
四、挑戰與未來方向
盡管Hadoop生態強大,但在支撐實時可視化方面也面臨挑戰:
- 實時性:傳統的MapReduce批處理延遲較高。解決方案是引入Spark Streaming、Flink等流處理框架,構建Lambda或Kappa架構,實現近實時數據處理和儀表盤更新。
- 交互式查詢性能:針對即席查詢(Ad-hoc Query)需求,可以搭配使用Impala、Presto或Druid等引擎,對HDFS或Hive中的數據實現秒級查詢響應,直接賦能交互式可視化分析。
- 數據治理與安全:在可視化過程中,需建立完善的數據權限管理體系,確保不同角色(如運營、管理員)看到其權限范圍內的數據可視化視圖。
結論
Hadoop大數據可視化是一個系統工程,它緊密連接著后端的數據處理、存儲服務與前端的業務洞察。CSDN等大型互聯網社區的實踐表明,有效利用Hadoop生態進行數據處理,并選擇合適的路徑將處理結果服務于可視化,是釋放大數據價值、提升產品智能與運營效率的必由之路。隨著實時計算與交互式分析的進一步融合,Hadoop生態系統將繼續在大數據可視化的底層支撐中扮演不可替代的角色。