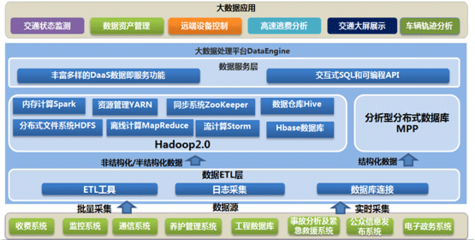
隨著城市化進程的加速與智能交通系統的普及,交通領域正以前所未有的速度生成海量、多源、實時的數據。如何高效地處理與存儲這些數據,并從中挖掘出提升交通效率、保障出行安全、優化城市管理的價值,已成為行業發展的關鍵課題。專業的交通大數據解決方案,其數據處理與存儲服務正是應對這一挑戰的核心引擎。
一、交通大數據的挑戰與數據處理需求
交通數據具有典型的“4V”特征:
- 體量巨大:來自攝像頭、雷達、地磁線圈、GPS、移動信令、公交卡、車載終端、社交媒體的數據每日以TB甚至PB級增長。
- 類型多樣:包括結構化數據(如車輛通行記錄)、半結構化數據(如GPS軌跡日志)和非結構化數據(如監控視頻、圖片)。
- 速度極快:實時交通流、突發事件監測等場景要求毫秒級的數據采集與處理響應。
- 價值密度低:海量數據中蘊含高價值信息比例小,需通過深度處理才能“沙里淘金”。
因此,數據處理服務必須能夠應對這些復雜性,實現數據的高效采集、實時/批量處理、深度融合與高質量治理。
二、數據處理服務的核心架構與流程
一套成熟的交通大數據處理服務通常遵循以下流程:
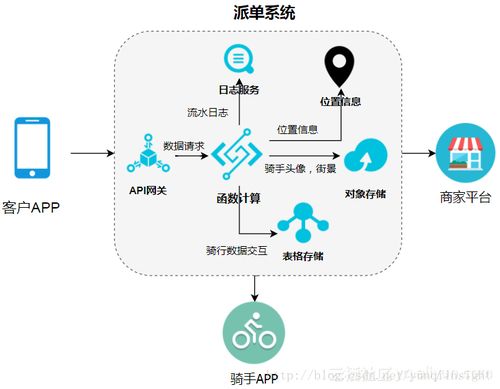
- 數據采集與接入:構建統一的數據接入平臺,支持物聯網協議、API接口、日志文件、流數據等多種方式,無縫集成路側設備、車輛、移動終端等多源數據。
- 數據清洗與標準化:通過規則引擎和算法模型,對原始數據進行去噪、糾錯、補全、格式標準化,消除“臟數據”,確保數據質量與一致性。例如,校正漂移的GPS點位,融合多源數據識別同一車輛。
- 實時流處理:針對交通擁堵預警、信號燈實時調控、事故快速檢測等場景,利用Flink、Spark Streaming等流計算框架,對數據流進行窗口計算、模式識別與復雜事件處理,實現秒級甚至毫秒級洞察。
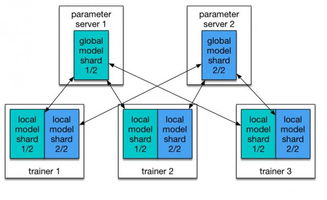
- 批處理與離線分析:對歷史數據進行大規模的ETL(提取、轉換、加載),運行復雜的機器學習模型,進行出行規律挖掘、路網承載力分析、長期規劃模擬等深度分析。
- 數據融合與關聯:打破數據孤島,將不同來源、不同維度的數據進行時空關聯與融合,形成完整的交通對象畫像(如車輛全行程軌跡)和事件全景視圖(如事故成因多維度分析)。
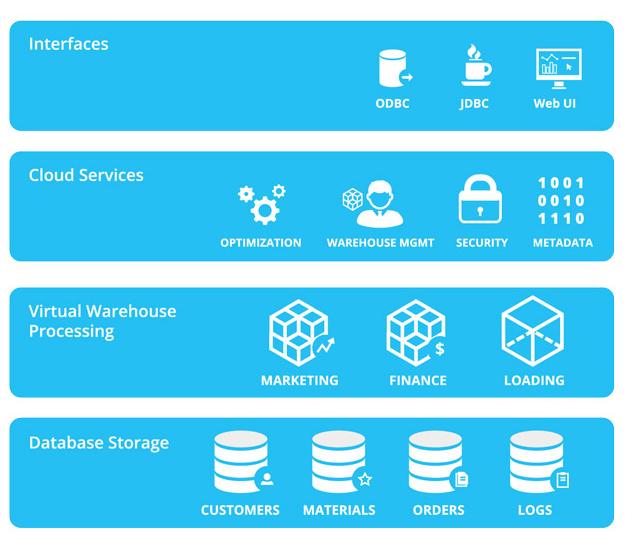
三、數據存儲服務的分層設計與技術選型
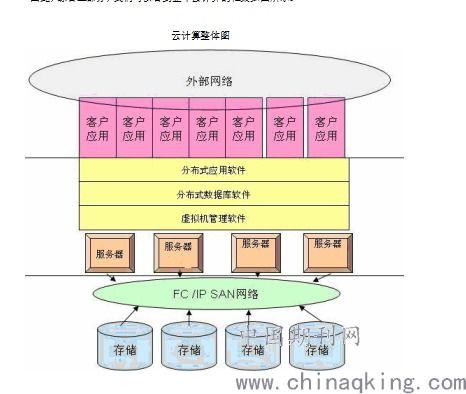
為滿足不同的訪問性能、成本和分析需求,交通大數據存儲通常采用分層、混合的架構:
- 實時熱存儲層:
- 用途:存儲近期的實時高并發訪問數據,如當前路況、實時信號燈狀態、在線車輛位置。
- 技術選型:分布式內存數據庫(如Redis)、時序數據庫(如InfluxDB, TDengine)或寬列數據庫(如Cassandra),以支持極低延遲的讀寫。
- 分析存儲層(數據湖/數據倉庫):
- 用途:存儲所有原始數據和處理后的明細數據、聚合數據,支撐交互式查詢、批處理和數據分析。
- 技術選型:
- 數據湖:基于HDFS或對象存儲(如AWS S3,阿里云OSS),以低成本存儲海量原始數據,保持數據原始形態,支持靈活的多模態分析。常與Hive、Spark、Presto等計算引擎結合。
- 數據倉庫:如ClickHouse、Greenplum或云上數倉(如Snowflake, MaxCompute),針對結構化數據優化,提供強大的OLAP分析能力,適合復雜的聚合查詢和報表生成。
- 冷備份/歸檔存儲層:
- 用途:存儲訪問頻率極低的歷史歸檔數據,滿足法規合規性要求。
- 技術選型:高壓縮比的廉價對象存儲或磁帶庫,顯著降低長期存儲成本。
四、數據處理與存儲服務的實踐價值
通過上述專業服務,交通管理部門與企業能夠:
- 提升運營效率:實現信號燈智能配時、公交線路動態優化、停車場資源智能調度,緩解擁堵。
- 增強安全水平:實時識別交通異常事件(如事故、違章)、預測事故高風險路段,實現主動預警與快速響應。
- 優化出行服務:為公眾提供精準的實時路況、個性化導航、智能停車誘導和一站式出行規劃(MaaS)。
- 賦能科學決策:基于長期歷史數據的深度分析,為道路規劃、基建投資、政策制定提供數據驅動的決策支持。
- 創新商業模式:支持車聯網服務、UBI保險、智慧物流等新業態的數據需求。
五、未來趨勢與展望
交通大數據處理與存儲服務將進一步向云原生、智能化、一體化演進:
- 云邊端協同:在邊緣節點進行數據預處理和實時決策,云端進行全局分析和模型訓練,形成高效協同的計算架構。
- AI深度融合:數據處理管道將深度集成AI能力,實現自動化的數據質量修復、智能分級存儲和實時預測分析。
- 數據安全與隱私保護:采用同態加密、聯邦學習、區塊鏈等技術,在數據充分流通與利用的確保敏感信息的安全與個人隱私合規。
強大而靈活的數據處理與存儲服務,是構建智慧交通“大腦”的基石。它不僅解決了海量數據的“存、管、用”難題,更將原始數據轉化為驅動交通系統智能化升級的寶貴資產,為構建安全、高效、綠色、以人為本的未來交通體系提供了無限可能。